| 专利名称 |
复杂动态环境下基于强化学习的机器人自主导航的模型训练方法 |
| 申请号/专利号 |
CN202511063822.9 |
专利权人(第一权利人) |
长春工业大学 |
| 申请日 |
2025-07-31 |
授权日 |
2025-10-10 |
| 专利类别 |
授权发明 |
战略新兴产业分类 |
新一代信息技术 |
| 技术主题 |
机器人|学习机|决策网络|训练方法|强化学习|仿真|多目标|游戏结构 |
| 应用领域 |
导航计算工具|设计优化/仿真|推理方法|神经学习方法 |
| 意向价格 |
具体面议 |
| 专利概述 |
本发明公开了一种复杂动态环境的基于强化学习的机器人自主导航方法,涉及强化学习、机器人导航等技术领域。本发明旨在解决多目标强化学习中,目标之间存在冲突,导致导航策略难以动态权衡、决策灵活性不足的问题。首先,创建仿真环境并构建Bayesian‑RVO模型用于对仿真环境中的行人行为模拟;其次,引入博弈论中的均衡响应原理设计奖励函数并构建博弈论框架;然后,设计基于Stackelberg博弈结构的双层决策网络;在此基础上,引入BNN结构的Critic网络;最后,进行模型训练。与现有方法相比,本发明在复杂环境下表现出更高的导航成功率、更低的碰撞率和更强的路径合理性,显著提升了机器人在复杂环境中的自主导航性能,可应用于农业、工业、服务业等领域。 |
| 图片资料 |
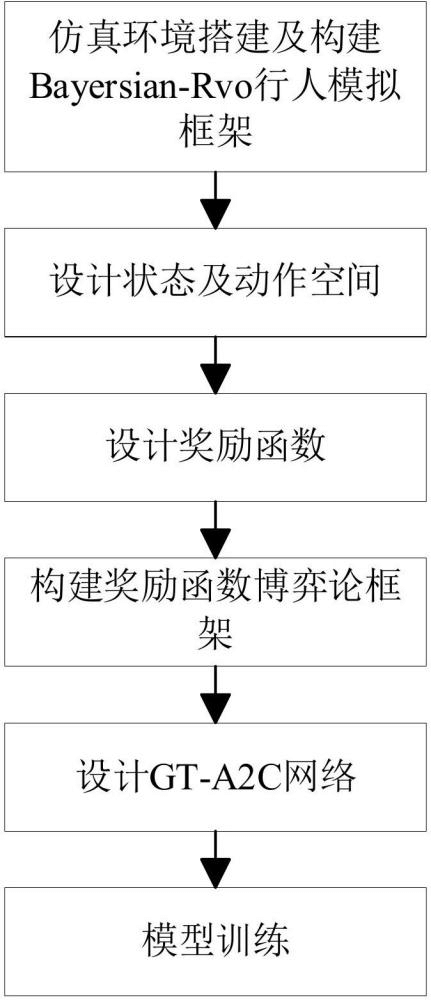
|
| 合作方式 |
具体面议 |
| 联系人 |
戚梅宇 |
联系电话 |
13074363281 |